"But what is the true measurement?"
Posted by: Gary Ernest Davis on: December 9, 2010
For several years, I attempted to teach pre-service teachers about the normal distribution through the distribution of measurement “errors”. I would find a male student who was willing to have his chest measured and ask other students in the class to take turns measuring his chest as accurately as possible – to the nearest 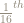

Students, of course, tried to be very accurate.
I, of course, knew that such repeated fine measurement of such a large object as a chest was going to produce a distribution of values. My plan was to get the students to show the differences around the average of their measurements.
If I had asked the students to measure to the nearest inch, a histogram of their measurements would most likely have produced something like the following:
 Asking them to measure to the nearest inch a chest that’s around 43″ pretty much guarantees very little variance: most, if not all, students will record a measurement of 43″.
Asking them to measure to the nearest inch a chest that’s around 43″ pretty much guarantees very little variance: most, if not all, students will record a measurement of 43″.
If, however, they have to measure to the nearest
A histogram of their measurements will now look more like this:
 Students will often ask at this point: “but what is the true measurement?”
Students will often ask at this point: “but what is the true measurement?”
My answer is that repeated measurement does not produce a number – it produces a distribution of numbers. The answer to the question: “How large is this man’s chest?” is not a number: it is a distribution. This distribution reflects the process of repeated measurement.
Reliability
It’s sort of obvious that if we use a relatively large measurement unit – such as 1″ to measure a 43″ chest, – several people’s independent measurements will give a very reliable result: pretty much 43″ every time. What is equally obvious is that as we decrease the unit of measurement – down, say, to
A single measurement returns a number. A series of independent measurements – which is at the basis of scientific replicability – returns a distribution of numbers, more or less spread out around the average.
The “true” measure
Just as students often ask what is the correct value for the chest measurement, so science, in its application of statistics, assumes there is a number that is the true measure, and that our measurement process is an attempt to estimate that true value. This is a hypothesis at best, and does not genuinely reflect the human nature of, and involvement in, measurement. Who has access to this “true” measurement is a mystery to me. The more accurately we try to measure, the more likely we are to obtain a spread-out distribution of measurements.
Every set of independent measurements will produce a distribution of numerical values and that distribution, like all other distributions, has certain descriptive properties such as central measures, measures of variation, measures of symmetry, and of peakedness (otherwise known as kurtosis).
The true score theory, or true measurement theory, postulates (and it is only a postulate) that a measurement value 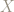
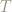


This postulate has an interesting consequence that I have rarely seen discussed. Suppose, as was the case in our pre-service teacher’s measurement process that measurements were carried out in a sequence, one following the other. This means – assuming a class size of 
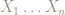
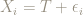
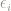
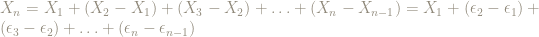
The terms 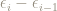

“So what?” you may ask.
Well, the above consequence of true score, or true measurement, theory does not mention the hypothesized “true value”
In other words, this consequence of true measurement theory, does not mention “true value” and sees repeated measurements as a random walk.
This “random walk theory” of measurement – for want of a better phrase – compels us to focus right from the beginning on the statistical aspects of measurement, rather then being side-tracked by a hypothetical “true value”.
Form this perspective, repeated measurements are a random walk, specified statistically by the nature of the “error” distribution.
That the “errors” generally follow a normal distribution is another, and deeper, story.
6 Responses to ""But what is the true measurement?""
2 | G
December 9, 2010 at 7:40 pm
Gary Davis took a point of view, and not a bad one to choose. Measuring a table length will not likely allow for much error compared to trying to measure someone’s chest. Peter Flom is answering his own question when he points to, “Standing in what position? At what point in his respiratory cycle? At what exact spot on his chest? etc.”
One could still think clearly about a TRUE VALUE, but this would be an idealization, possibly dependant upon a definition including precisely stated conditions.
3 | David Radcliffe
December 12, 2010 at 1:34 pm
Counting ballots is another example. We want to believe that the number of votes for each candidate is well-defined. Perhaps it would be, if all voters marked the ballots properly. In reality, the totals will be different each time the votes are counted, especially if the ballots are recounted by hand, so they should be regarded as random variables.
4 | Richard Green
December 16, 2010 at 9:46 am
No matter what you are measuring and with what instrument, what you are actually getting is 1) a value & 2) a degree of error such as “43 inches plus or minus 1/2 inch” in this case. Often knowing the degree of error can be as important as the actual measurement.
If you are working on a project where the components have to be built to a precision of +/-1 mm, using screws that vary in construction +/- 1.5mm probably won’t do the job.
Leave a Reply to Gary DavisCancel reply

December 9, 2010 at 3:41 pm
I don’t know if I buy this …. and, since my degree is in psychometrics, you are speaking my language. But let’s leave psychological measures aside (at least for now) and concentrate on physical measurements.
First we have to define what we mean by “true measurement”. This isn’t always clear, and measuring a person’s chest is far from the simplest example. Suppose we try to measure something that doesn’t change size constantly – like the length of a table. Well, even then, it’s true we can’t know it EXACTLY, unless we don’t want to know where it is (Heisenberg and that stuff), but we can know it quite precisely if we use a good measuring system; we could probably measure it closely enough that we got the same value to the 1/16th of an inch or even less = I’m not sure what device would be best. But if we gave students tape measures there would be a spread, because that’s not a very precise way of measuring things.
Now, if we then move to the guy’s chest (what would you do if ALL the students were women? :-)), it’s not so clear what we even mean by “how big is his chest?” Standing in what position? At what point in his respiratory cycle? At what exact spot on his chest? etc. So, now we have two sources of error: Measurement error and what could be called model error.
If there is no true score, what are the errors centered around?
December 9, 2010 at 3:50 pm
Thanks for this detailed comment.
“If there is no true score, what are the errors centered around?”
The experimental mean.